Studi-tools.de
Update 2012-11-07: My uni decided to put the schedule and room information behind a login so I my scripts can no longer access those. As such the project is pretty much dead. This is especially sad since the tools the uni offers are - let's say lacking.
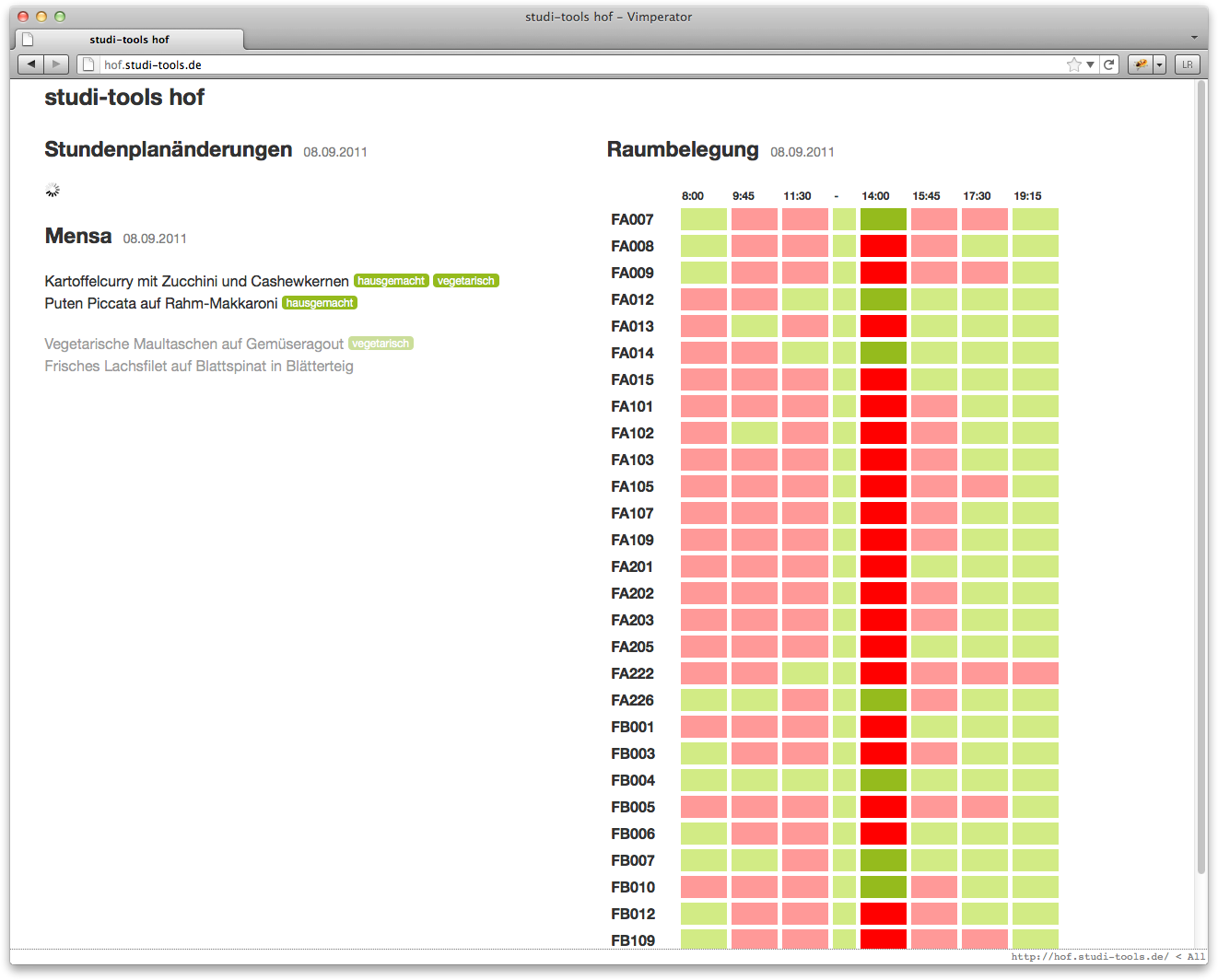
This is a personal long-term project of mine. The basic idea is to provide all the things I want to know as a student about today at a glance. We have schedule changes, todays mensa menu and which rooms are occupied at what times. It's all pretty basic and I have a huge list of stuff I'd like to do when nothing else is up (you know that's one of those chilly days in hell) but it gets the job done.
Frontend
Technology wise this was my first try at a all JavaScript site that accesses a RESTful API as its backend. This allows for a pretty radical caching strategy for the HTML/JavaScript part of the page. Since the page would be accessed via smartphone quite a bit (poor students with high-end hardware and such) I reasoned it wouldn't hurt to go for mobile optimization.
I saw that as a chance to go all out and pretty much threw all the optimization techniques at the code I could come up with. The JavaScript gets minified with Google's Closure Compiler then injected into the HTML via script-tag. All this is run through htmlcompressor and served with maximum cache expire time. Furthermore I started to reimplement the JavaScript code with Ender instead of jQuery for minimal redundant code. This aspiring endeavor did not come to fruition yet though.
Backend
On the backend/API side I went with the Tornado framework. If you ask me why I'll tell you to be able to handle the many request on my small vServer but in reality I just wanted to play around with the hip event driven coding thing. Though having worked quite nicely the last few months it seems the site throws errors these days which probably means I should get around to fix it sometime.
Scraping is done by a few lines of custom Python code utilizing lxml in combination with Eventlet. Using Eventlet makes it possible to retrieve multiple URLs at the same time which makes the whole scraping affair a whole lot more efficient. The downside of this is that I hit the servers quite often and pretty fast which makes me fear one day they'll notice and ban my scraper. On the other hand my scraper is nothing in comparison to Googlebot I imagine.
Data is translated to JSON and permanently cached on disk. So whenever the API is hit all there is to answering is to fetch the right answer from the database.
Future
Future plans (of which I have many) include rewriting the backend to use a NoSQL data store. Right now it caches the scraped data as serialized chunks of data in a SQLite database which works but feels a bit too much for the job. So I was playing with the idea of giving LevelDB a shot. LevelDB seems to be the NoSQL equivalent to SQLite and should simplify storing the JSON data a bit. We will see how that turns out.